Avec les copains, on discute au quotidien sur une chatroom XMPP. Ça s’appelle un MUC, ou “Multi-User Chat”, c’est défini dans la XEP-0045 et ça ressemble à ce qu’on connaît sur IRC.
Dans notre cas, ce MUC est hébergé sur mon serveur XMPP personnel (un Prosody), et n’importe quelle personne autorisée peut le rejoindre avec un compte XMPP quelconque, pas besoin d’être inscrit sur mon serveur, c’est la beauté du modèle fédéré de XMPP.
Au bout de plusieurs mois passés à déblatérer des conneries au quotidien, on se dit que ça pourrait être rigolo de faire des stats sur tout ça : les mots revenant le plus souvent, les gens les plus actifs, l’évolution de telle ou telle expression, etc. De plus, faisant joujou actuellement avec la stack ELK, c’était l’occasion rêvée d’indexer les messages dans Elasticsearch pour pouvoir ensuite traficoter tout ça dans Kibana.
La source
Le plus gros problème que j’ai rencontré a été de choisir la source idéale pour réaliser cette indexation.
J’ai naturellement commencé par regarder du côté de mod_muc_log, le format est imbitable et puis logger les messages dans le désordre ? sérieusement ? Les autres modules de logging sous Prosody sont par ailleurs surtout orientées “messages privés” et ne supportent pas correctement les MUC.
Le salut est venu d’un module que j’utilise depuis 1 an, mod_mam_muc, et qui permet de stocker l’historique des conversations afin de pouvoir le fournir à un client compatible avec la XEP-0313 : sous le magnifique client Android Conversations, c’est ce qui permet de scroller vers le haut de manière illimitée, le serveur XMPP fournissant l’historique à la demande. (mod_mam_muc le fait pour les chatrooms, mod_mam pour les conversations privées)
Ce module permet d’utiliser plusieurs backends, à l’époque j’avais choisi MySQL pour stocker et requêter ça sur mon serveur MariaDB. Ce qui fait qu’en fait, je dispose de tout l’historique, alimenté en temps réel, dans une base SQL \o/
Dans la base, un message ressemble à ça :
MariaDB [prosody]> select * from prosodyarchive where sort_id='148659';
+---------+--------------+-------+---------+--------------------------------------+------------+-------------------+------+---------------------------------------------------------------------------------------------------------------------------------+
| sort_id | host | user | store | key | when | with | type | value |
+---------+--------------+-------+---------+--------------------------------------+------------+-------------------+------+---------------------------------------------------------------------------------------------------------------------------------+
| 148659 | meow.iono.me | posay | muc_log | 7333a81a-4f4a-4557-8051-9567fbf840a1 | 1481968848 | message<groupchat | xml | <message id='prof_27086' type='groupchat' to='posay@meow.iono.me' from='posay@meow.iono.me/laifen'><body>matin</body></message> |
+---------+--------------+-------+---------+--------------------------------------+------------+-------------------+------+---------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
On a tout ce qu’on veut : des identifiants uniques, un timestamp, le pseudo et le message stocké en XML. Plus qu’à extraire et parser tout ça.
L’extraction
Au début, j’avais pensé faire un dump régulier dans un fichier type CSV que j’aurais donné à parser à Logstash, mais bof. (il faut gérer la position dans la table, faire tourner un agent sur mon serveur MariaDB, etc)
Et je suis tombé là-dessus : https://www.elastic.co/blog/logstash-jdbc-input-plugin
Un plugin livré en standard dans Logstash depuis 2015 et qui permet d’utiliser n’importe quel module JDBC pour se connecter à une base et extraire des données. Ça gère la position suivant un index que l’on peut définir, ça dispose d’une cron intégrée, bref c’est top.
L’article linké plus haut montre bien comment ça marche, et la doc est très claire également.
Ensuite, il reste à parser le XML contenu dans le champ value, j’avais commencé de manière crado avec un filter grok et une regex, cela fonctionnait mais je suis au final passé par le filter xml, ce qui est bien plus propre.
Du coup, voilà ma conf de pipeline Logstash, c’est utilisable directement avec votre prosody et mod_mam_muc stocké dans MySQL :
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://<yourmysqlserverip>/prosody"
jdbc_user => "<yourdbuser>"
jdbc_password => "<yourdbpasswd>"
jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
statement => "select prosodyarchive.sort_id,prosodyarchive.key,prosodyarchive.when,prosodyarchive.value from prosodyarchive where prosodyarchive.sort_id>:sql_last_value"
tracking_column => sort_id
use_column_value => true
last_run_metadata_path => "/srv/logstash/states/xmpp_muc_last_run"
schedule => "*/5 * * * *"
}
}
filter {
xml {
force_array => false
force_content => true
# the xml filter will parse the xml string contained in the 'value' field
source => "value"
# all values extracted from xml are put in the 'muc_array' array field
target => "muc_array"
# we extract individual values from the array to string fields
add_field => {
"muc_id" => "%{[muc_array][id]}"
"muc_nick" => "%{[muc_array][from]}"
"muc_to" => "%{[muc_array][to]}"
"muc_type" => "%{[muc_array][type]}"
"muc_message" => "%{[muc_array][body][content]}"
}
}
# we drop all messages not related to our MUC
if ! ( [muc_type] == "groupchat" and [muc_to] == "mymuc@myxmppserver.com" ) {
drop {}
}
# we convert the MAM unix timestamp to a valid ES timestamp
date {
match => ["when", "UNIX"]
}
mutate {
# we drop some fields that are now useless
remove_field => [
"sort_id",
"value",
"muc_array",
"muc_to",
"when"
]
# for clarity
rename => {
"key" => "xmpp_id"
}
# we convert the full xmpp 'from' field to a simple nickname
gsub => [
"muc_nick", ".*@.*/", ""
]
}
}
output {
elasticsearch {
hosts => [ "<yourelasticssearchip>:9200" ]
index => "xmpp_muc"
document_id => "%{xmpp_id}"
}
}
Les directives tracking_column et last_run_metadata_path permettent de stocker dans le fichier /srv/logstash/states/xmpp_muc_last_run la valeur de sort_id du dernier message extrait, afin de ne pas reprendre l’extraction à zéro à chaque fois, celle-ci commencera toujours à partir du sort_id immédiatement supérieur.
Le gros du filtrage est fait par le filter xml qui jette toutes les entrées n’étant pas des messages (pour ne pas récupérer les présences et autres) et ne faisant pas partie de notre MUC. Il réalise également auparavant l’extraction de toutes les données utiles dans des champs séparés de notre document Elasticsearch final.
Le dernier point à mentionner est la déclaration de notre champ xmpp_id (qui est un UUID généré par Prosody) en tant que document_id de notre index Elasticsearch : si l’extraction est relancée depuis zéro (volontairement ou non), cela permet de ne pas dupliquer les documents, les messages déjà présents seront simplement mis à jour dans les documents existants si les données ont changé (ce qui ne sera normalement jamais le cas)
Le résultat
L’extraction et l’indexation sont si rapides (7-8min sur mon serveur pour 100K messages) que la réaliser toutes les 5 minutes n’est pas un problème sur la plupart des MUC, seuls les nouveaux messages étant extraits à chaque fois.
Et voici ce que cela donne sur une visualisation simple dans Kibana :
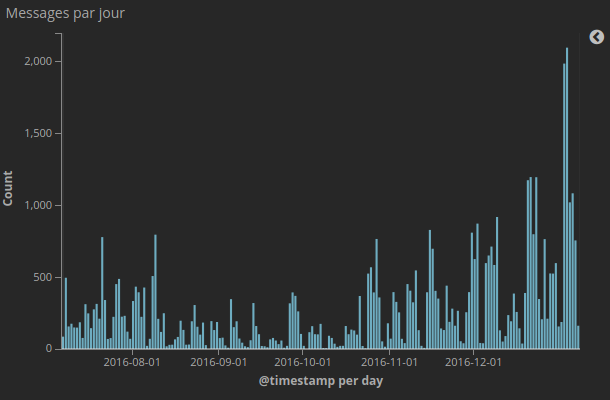
Enjoy :)